Ambari is web-based tool for
provisioning, managing, and monitoring Apache Hadoop clusters which includes
support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper,
Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster
health such as heatmaps and ability to view MapReduce, Pig and Hive
applications visually alongwith features to diagnose their performance
characteristics in a user-friendly manner.
The Apache Ambari project is aimed at making Hadoop
management simpler by developing software for provisioning, managing, and
monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use
Hadoop management web UI backed by its RESTful APIs.
- ·
Ambari enables System
Administrators to:
- o
Provision
a Hadoop Cluster
- o
Ambari
provides a step-by-step wizard for installing Hadoop services across any number
of hosts.
- o
Ambari
handles configuration of Hadoop services for the cluster.
- ·
Manage
a Hadoop Cluster
- o
Ambari provides central
management for starting, stopping, and reconfiguring Hadoop services across the
entire cluster.
- ·
Monitor
a Hadoop Cluster
- o
Ambari provides a dashboard
for monitoring health and status of the Hadoop cluster.
- o
Ambari leverages Ganglia for metrics
collection.
- o
Ambari leverages Nagios for system alerting and will
send emails when your attention is needed (e.g., a node goes down, remaining
disk space is low, etc).
- ·
Ambari enables Application
Developers and System Integrators to:
- o
Easily integrate Hadoop
provisioning, management, and monitoring capabilities to their own applications
with the Ambari REST
APIs.
·
RHEL (Redhat Enterprise
Linux) 5 and 6
·
CentOS 5 and 6
·
OEL (Oracle Enterprise
Linux) 5 and 6
·
SLES (SuSE Linux Enterprise
Server) 11
·
Ubuntu
12
(Alternative to YARN) -
The Mesos kernel runs on every machine and provides applications (e.g., Hadoop,
Spark, Kafka, Elastic Search) with API’s for resource management and scheduling
across entire datacenter and cloud environments.
Twitter developed to automate its infrastructure. Used
by EBay, AirBnB, Netflix and HubSpot
Features:
- Scalability
to 10,000s of nodes
- Fault-tolerant
replicated master and slaves using ZooKeeper
- Support
for Docker containers
- Native
isolation between tasks with Linux Containers
- Multi-resource
scheduling (memory, CPU, disk, and ports)
- Java,
Python and C++ APIs for developing new parallel applications
- Web
UI for viewing cluster state
Apache Mesos is
a cluster manager that lets users run multiple Hadoop jobs, or other
high-performance applications, on the same cluster at the same time.
Docker is an open platform
for developers and sysadmins to build, ship, and run distributed applications
Apache ZooKeeper is an effort to develop and maintain
an open-source server which enables highly reliable distributed coordination.
ZooKeeper is a centralized service for maintaining configuration information,
naming, providing distributed synchronization, and providing group services.
All of these kinds of services are used in some form or another by distributed
applications.
The Apache™ Hadoop® project
develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software
library is a framework that allows for the distributed processing of large data
sets across clusters of computers using simple programming models. It is
designed to scale up from single servers to thousands of machines, each offering
local computation and storage. Rather than rely on hardware to deliver
high-availability, the library itself is designed to detect and handle failures
at the application layer, so delivering a highly-available service on top of a
cluster of computers, each of which may be prone to failures.
The project includes these
modules:
A distributed file system
that provides high-throughput, fault tolerant storage.
A framework for job
scheduling and cluster resource management.
A YARN-based system for
parallel processing of large data sets.
Apache HBase™ is the Hadoop database, a distributed, scalable,
big data store. Use Apache HBase™ when
you need random, realtime read/write access to your Big Data. This project's
goal is the hosting of very large tables -- billions of rows X millions of
columns -- atop clusters of commodity hardware.
It stores data
as key/value pairs. It's basically a database, a NoSQL
database and like any other database it's biggest
advantage is that it provides you random read/write capabilities. Hbase data can be accessed via their own API
or using MapReduce jobs.
The Apache Hive ™ data
warehouse software facilitates querying and managing large datasets residing in
distributed storage. Hive provides a mechanism to project structure onto this
data and query the data using a SQL-like language called HiveQL. At the same
time this language also allows traditional map/reduce programmers to plug in
their custom mappers and reducers when it is inconvenient or inefficient to
express this logic in HiveQL. HDFS files
as well as HBase Tables can be mapped in Hive and queried using HiveQL.
HCatalog is a table and
storage management layer for Hadoop that enables users with different data
processing tools — Pig, MapReduce — to more easily read and write data on the
grid. HCatalog’s table abstraction presents users with a relational view of
data in the Hadoop distributed file system (HDFS) and ensures that users need
not worry about where or in what format their data is stored — RCFile format,
text files, SequenceFiles, or ORC files.
HCatalog supports reading
and writing files in any format for which a SerDe (serializer-deserializer) can
be written. By default, HCatalog supports RCFile, CSV, JSON, and SequenceFile,
and ORC file formats. To use a custom format, you must provide the InputFormat,
OutputFormat, and SerDe.
Hadoop MapReduce is a software
framework for easily writing applications which process vast amounts of data
(multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes)
of commodity hardware in a reliable, fault-tolerant manner.
A MapReduce job usually splits the input data-set into
independent chunks which are processed by the map tasks in a completely parallel manner. The
framework sorts the outputs of the maps, which are then input to the reduce
tasks. Typically both the input and the output of the job are
stored in a file-system. The framework takes care of scheduling tasks,
monitoring them and re-executes the failed tasks.
·
Hbase supports MapReduce jobs as well as their own Java
API to push and pull data.
·
Hive supports MapReduce jobs as well as their own query
language which also gets converted to MapReduce jobs
·
PIG is a highlevel language for expressing data
analysis programs that when compiled generate a series of MapReduce jobs.
Do BI-style Queries on
Hadoop : Impala provides low latency and high concurrency for BI/analytic
queries on Hadoop (not delivered by batch frameworks such as Apache Hive).
Impala also scales linearly, even in multitenant environments.
Unify Your Infrastructure:
Utilize the same file and data formats and metadata, security, and resource
management frameworks as your Hadoop deployment—no redundant infrastructure or
data conversion/duplication.
Implement Quickly: For Apache Hive users, Impala utilizes the
same metadata, ODBC driver, SQL syntax, and user interface as Hive—so you don't
have to worry about re-inventing the implementation wheel.
A fast and general compute
engine for Hadoop data. Spark provides a simple and expressive programming
model that supports a wide range of applications, including ETL, machine
learning, stream processing, and graph computation. Spark runs on Hadoop, Mesos, standalone, or
in the cloud. It can access diverse data sources including HDFS, Cassandra,
HBase, S3
https://spark.apache.org/
Drill provides a JSON-like internal data model to
represent and process data. The flexibility of this data model allows Drill to
query, without flattening, both simple and complex/nested data types as well as
constantly changing application-driven schemas commonly seen with Hadoop/NoSQL
applications. Drill also provides intuitive extensions to SQL to work with
complex/nested data types.
With Drill, businesses can minimize switching costs and
learning curves for users with the familiar ANSI SQL syntax. Analysts can continue
to use familiar BI/analytics tools that assume and auto-generate ANSI SQL code
to interact with Hadoop data by leveraging the standard JDBC/ODBC interfaces
that Drill exposes.
Apache Drill is an open source, low latency SQL query
engine for Hadoop and NoSQL.
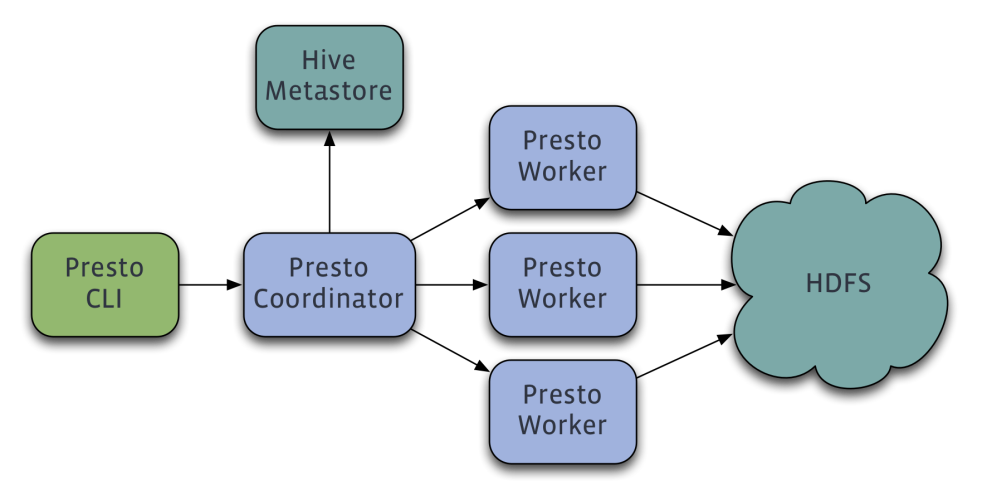
Presto is a distributed system that runs on a cluster
of machines. A full installation includes a coordinator and multiple workers.
Queries are submitted from a client such as the Presto CLI to the coordinator.
The coordinator parses, analyzes and plans the query execution, then
distributes the processing to the workers.
Presto supports reading Hive data from the following
versions of Hadoop:
Apache Hadoop 1.x
Apache Hadoop 2.x
Cloudera CDH 4
Cloudera CDH 5
The following file formats are supported: Text,
SequenceFile, RCFile, ORC
Additionally, a remote Hive metastore is required.
Local or embedded mode is not supported. Presto does not use MapReduce and thus
only requires HDFS.
R is the world’s most
powerful programming language for statistical computing, machine learning and
graphics. RHadoop is a collection of
five R packages that allow users to manage and analyze data with Hadoop.
Apache Storm is a free and open
source distributed
realtime computation system. Storm makes it easy to reliably process unbounded
streams of data, doing for realtime processing what Hadoop did for batch
processing. Storm is simple, can be used with any programming
language.
Storm has many use cases: realtime analytics, online machine learning,
continuous computation, distributed RPC, ETL, and more. Storm is fast.
Storm integrates with the queueing and database
technologies you already use. A Storm topology consumes streams of data and
processes those streams in arbitrarily complex ways, repartitioning the streams
between each stage of the computation however needed.
H2O is the open source in memory solution from 0xdata for predictive
analytics on big data. It is a math and machine learning engine that brings
distribution and parallelism to powerful algorithms that enable you to make
better predictions and more accurate models faster. With familiar APIs like R
and JSON, as well as common storage method of using HDFS, H2O can bring the
ability to do advance analyses to a broader audience of users.
http://hortonworks.com/hadoop-tutorial/predictive-analytics-h2o-hortonworks-data-platform/
Currently Mahout supports mainly three use cases: Recommendation mining
takes users' behavior and from that tries to find items users might like. Clustering
takes e.g. text documents and groups them into groups of topically related
documents. Classification learns from exisiting categorized documents what
documents of a specific category look like and is able to assign unlabelled
documents to the (hopefully) correct category.
The Mahout community decided to move its codebase onto modern data
processing systems that offer a richer programming model and more efficient
execution than Hadoop MapReduce. Mahout
will therefore reject new MapReduce algorithm implementations from now on.
A robust content curation technology to save time
finding the content you need.
An intuitive publishing platform that lets you publish it easily wherever you'd
like and reach your goals . Sqoop is a tool
that allows you to transfer data between relational databases and Hadoop. It
supports incremental loads of a single table or a free form SQL query as well
as saved jobs which can be run multiple times to import updates made to a
database since the last import. Not only this, imports can also be used to
populate tables in Hive or HBase. Along with this Sqoop also allows you to
export the data back into the relational database from the cluster.
(Aggregation)Flume is a distributed,
reliable, and available service for efficiently collecting, aggregating, and
moving large amounts of log data. It has a simple and flexible architecture
based on streaming data flows. It is robust and fault tolerant with tunable
reliability mechanisms and many failover and recovery mechanisms. It uses a
simple extensible data model that allows for online analytic application http://flume.apache.org/
Apache Kafka is
publish-subscribe messaging rethought as a distributed commit log.
Fast
A single Kafka broker can handle hundreds of megabytes of reads and writes per
second from thousands of clients.
Scalable
Kafka is designed to allow a single cluster to serve as the central data
backbone for a large organization. It can be elastically and transparently
expanded without downtime. Data streams are partitioned and spread over a
cluster of machines to allow data streams larger than the capability of any
single machine and to allow clusters of co-ordinated consumers
Durable
Messages are persisted on disk and replicated within the cluster to prevent
data loss. Each broker can handle terabytes of messages without performance
impact.
Distributed by Design
Kafka has a modern cluster-centric design that offers strong durability and
fault-tolerance guarantees.
Avro is a data serialization system. It provides functionalities similar to systems like Protocol
Buffers, Thrift etc. In addition to that it provides some other significant
features like rich data structures, a compact, fast, binary data format, a
container file to store persistent data, RPC mechanism and pretty simple
dynamic languages integration. And the best part is that Avro can easily be
used with MapReduce, Hive and Pig. Avro uses JSON for
defining data types.
Oozie
is a workflow scheduler system to manage Apache Hadoop jobs. Oozie Workflow jobs are Directed Acyclical
Graphs (DAGs) of actions. Oozie
Coordinator jobs are recurrent Oozie Workflow jobs triggered by time
(frequency) and data availabilty. Oozie
is integrated with the rest of the Hadoop stack supporting several types of
Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig,
Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs
and shell scripts). Oozie is a scalable,
reliable and extensible system.







{kind=link}